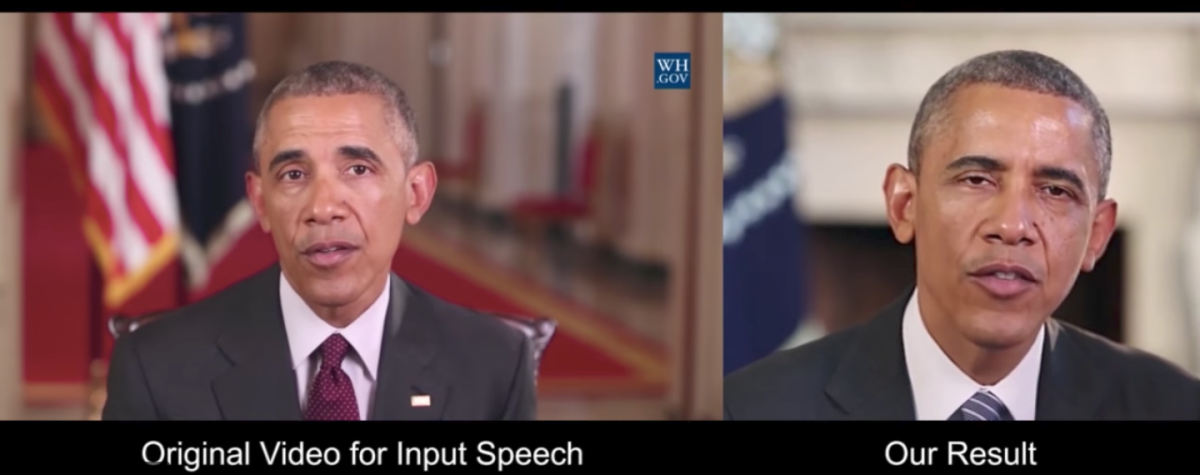
Artificial intelligence software could generate highly realistic fake videos of former president Barack Obama using existing audio and video clips of him, a new study [PDF] finds.
Such work could one day help generate digital models of a person for virtual reality or augmented reality applications, researchers say.
Computer scientists at the University of Washington previously revealed they could generate digital doppelgängers of anyone by analyzing images of them collected from the Internet, from celebrities such as Tom Hanks and Arnold Schwarzenegger to public figures such as George W. Bush and Barack Obama. Such work suggested it could one day be relatively easy to create such models of anybody, when there are untold numbers of digital photos of everyone on the Internet.
The researchers chose Obama for their latest work because there were hours of high-definition video of him available online in the public domain. The research team had a neural net analyze millions of frames of video to determine how elements of Obama’s face moved as he talked, such as his lips and teeth and wrinkles around his mouth and chin.
In an artificial neural network, components known as artificial neurons are fed data, and work together to solve a problem such as identifying faces or recognizing speech. The neural net can then alter the pattern of connections among those neurons to change the way they interact, and the network tries solving the problem again. Over time, the neural net learns which patterns are best at computing solutions, an AI strategy that mimics the human brain.
In the new study, the neural net learned what mouth shapes were linked to various sounds. The researchers took audio clips and dubbed them over the original sound files of a video. They next took mouth shapes that matched the new audio clips and grafted and blended them onto the video. Essentially, the researchers synthesized videos where Obama lip-synched words he said up to decades beforehand.
The researchers note that similar previous research involved filming people saying sentences over and over again to map what mouth shapes were linked to various sounds, which is expensive, tedious and time-consuming. In contrast, this new work can learn from millions of hours of video that already exist on the Internet or elsewhere.
One potential application for this new technology is improving videoconferencing, says study co-author Ira Kemelmacher-Shlizerman at the University of Washington. Although teleconferencing video feeds may stutter, freeze or suffer from low-resolution, the audio feeds often work, so in the future, videoconferencing may simply transmit audio from people and use this software to reconstruct what they might have looked like while they talked. This work could also help people talk with digital copies of a person in virtual reality or augmented reality applications, Kemelmacher-Shlizerman says.
The researchers note their videos are currently not always perfect. For example, when Obama tilted his face away from the camera in a target video, imperfect 3-D modeling of his face could cause parts of his mouth to get superimposed outside the face and onto the background.
In addition, the research team notes their work did not model emotions, and so Obama’s facial expressions in the output videos could appear too serious for casual speeches or too happy for serious speeches. However, they suggest that it would be interesting to see if their neural network could learn to predict emotional states from audio to produce corresponding visuals.
The researchers were careful to not generate videos where they put words in Obama’s mouth that he did not at some other time utter himself. However, such fake videos are “likely possible soon,” says study lead author Supasorn Suwajanakorn, a computer scientist at the University of Washington.
However, this new research also suggests ways to detect fake videos in the future. For instance, the video manipulation the researchers practiced can blur mouths and teeth. “This may be not noticeable by human eyes, but a program that compares the blurriness of the mouth region to the rest of the video can easily be developed and will work quite reliably,” Suwajanakorn says.
The researchers speculated that the link between mouth shapes and utterances may be to some extent universal for people. This suggests that a neural network trained on Obama and other public figures could be adapted to work for many different people.
The research was funded by Samsung, Google, Facebook Intel and the University of Washington. The scientists will detail their findings [PDF] on Aug. 2 at the SIGGRAPH conference in Los Angeles.
__
This article and images was originally posted on [IEEE Spectrum Robotics] July 12, 2017 at 10:02AM
By





![[NSFW] Has AI gone too far? DeepTingle turns El Reg news into terrible erotica](https://esistme.wordpress.com/wp-content/uploads/2017/05/1364.jpg?w=1024)